LLMs in financial world and Internet-scale Financial Data
The demos are shown in FinGPT and the data sources and supporting codes are in FinNLP
中文版请点击这里
Disclaimer: We are sharing codes for academic purpose under the MIT education license. Nothing herein is financial advice, and NOT a recommendation to trade real money. Please use common sense and always first consult a professional before trading or investing.
Ⅰ. Architecture
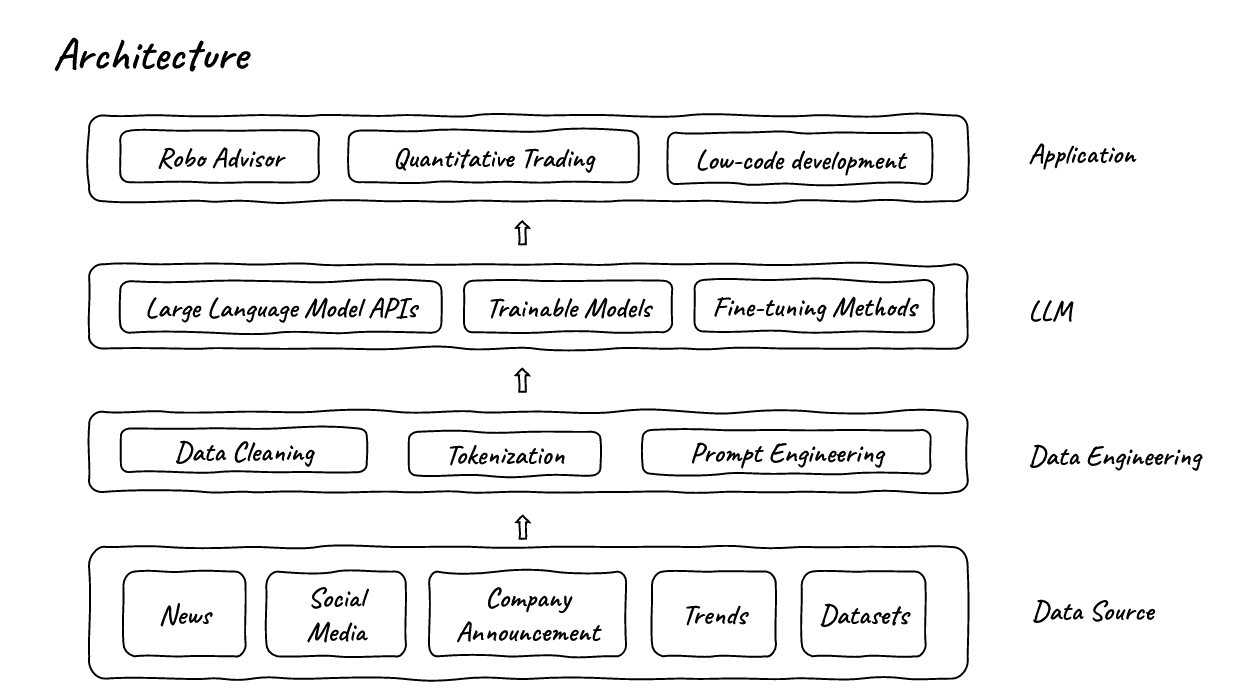
-
The whole project is made up of 4 parts:
-
The first part is the Data Source, Here, we gather past and streaming data from the Internet.
-
Next, we push the data to the Data Engineering part where we clean the data, tokenize the data and do the prompt engineering
-
Then, the data is pushed to LLMs. Here, we may use LLMs in different kind of ways. We can not only use the collected data to train our own light-weight fine-tuning models but we can also use those data and trained models or LLM APIs to support our applications
- The last part would be the application part, here we can use data and LLMs to make many interesting applications.
Ⅱ. Data Sources
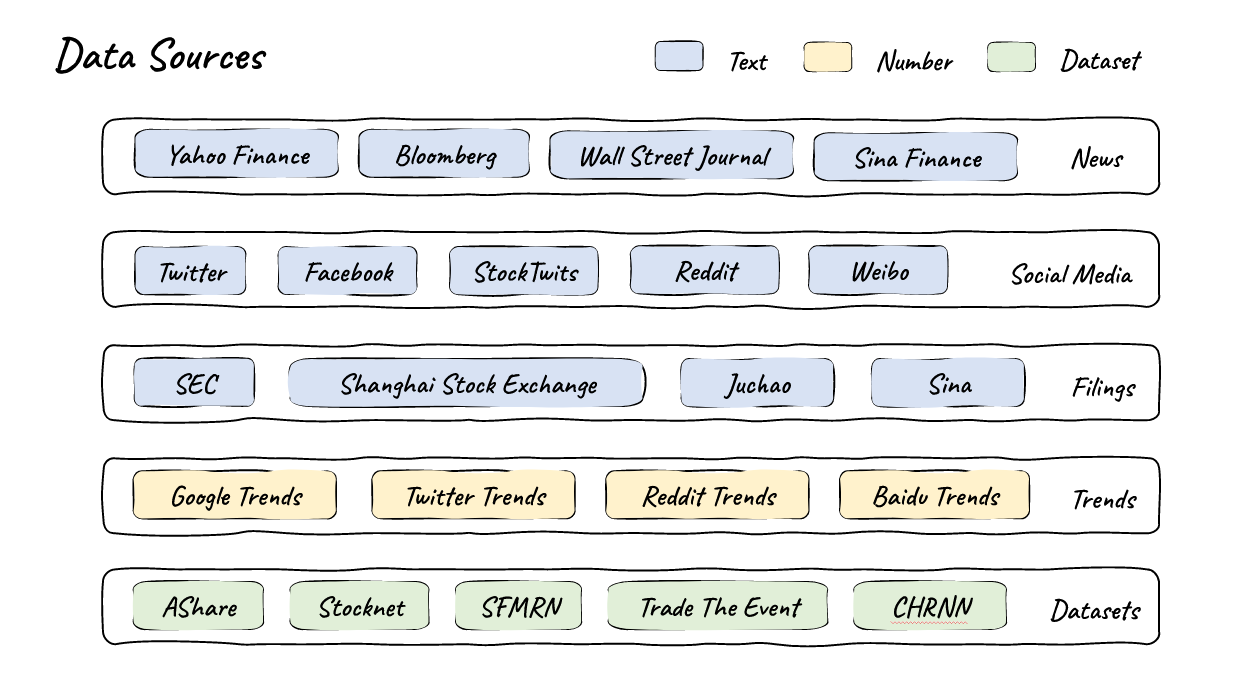
- Due to space limitations, we only show a few of them.
1. News
| Platform | Data Type | Related Market | Specified Company | Range Type | Source Type | Limits | Docs (1e4) | Support |
|---|---|---|---|---|---|---|---|---|
| Yahoo | Financial News | US Stocks | √ | Date Range | Official | N/A | 1,500+ | √ |
| Reuters | Financial News | US Stocks | × | Date Range | Official | N/A | 1,500+ | √ |
| Sina | Financial News | CN Stocks | × | Date Range | Official | N/A | 2,000+ | √ |
| Eastmoney | Financial News | CN Stocks | √ | Date Range | Official | N/A | 1,000+ | √ |
| Yicai | Financial News | CN Stocks | √ | Date Range | Official | N/A | 500+ | Soon |
| CCTV | Governemnt News | CN Stocks | × | Date Range | Third party | N/A | 4 | √ |
| US Mainstream | Financial News | US Stocks | √ | Date Range | Third party | Account (Free) | 3,200+ | √ |
| CN Mainstream | Financial News | CN Stocks | × | Date Range | Third party | ¥500/year | 3000+ | √ |
- FinGPT may have fewer docs than Bloomberg, we're on the same order of magnitude.
2. Social Media
| Platform | Data Type | Related Market | Specified Company | Range Type | Source Type | Limits | Docs (1e4) | Support |
|---|---|---|---|---|---|---|---|---|
| Tweets | US Stocks | √ | Date Range | Official | N/A | 18,000+ | √ | |
| StockTwits | Tweets | US Stocks | √ | Lastest | Official | N/A | 160,000+ | √ |
| Reddit (wallstreetbets) | Threads | US Stocks | × | Lastest | Official | N/A | 9+ | √ |
| Tweets | CN Stocks | √ | Date Range | Official | Cookies | 1,400,000+ | √ | |
| Tweets | CN Stocks | √ | Lastest | Official | N/A | 1,400,000+ | √ |
- In BloomberGPT, they don’t collect social media data, but we believe that public opinion is one of the most important factors interfering the stock market.
3. Company Announcement
| Platform | Data Type | Related Market | Specified Company | Range Type | Source Type | Limits | Docs (1e4) | Support |
|---|---|---|---|---|---|---|---|---|
| Juchao (Official Website) | Text | CN Stocks | √ | Date Range | Official | N/A | 2,790+ | √ |
| SEC (Official Website) | Text | US Stocks | √ | Date Range | Official | N/A | 1,440+ | √ |
- Since we collect data from different stock markets, we have more filing docs than Bloomberg GPT.
4. Trends
| Platform | Data Type | Related Market | Data Source | Specified Company | Range Type | Source Type | Limits |
|---|---|---|---|---|---|---|---|
| Google Trends | Index | US Stocks | Google Trends | √ | Date Range | Official | N/A |
| Baidu Index | Index | CN Stocks | Soon | - | - | - | - |
5. Data Sets
| Data Source | Type | Stocks | Dates | Avaliable |
|---|---|---|---|---|
| AShare | News | 3680 | 2018-07-01 to 2021-11-30 | √ |
| stocknet-dataset | Tweets | 87 | 2014-01-02 to 2015-12-30 | √ |
| CHRNN | Tweets | 38 | 2017-01-03 to 2017-12-28 | √ |
Ⅲ. Models
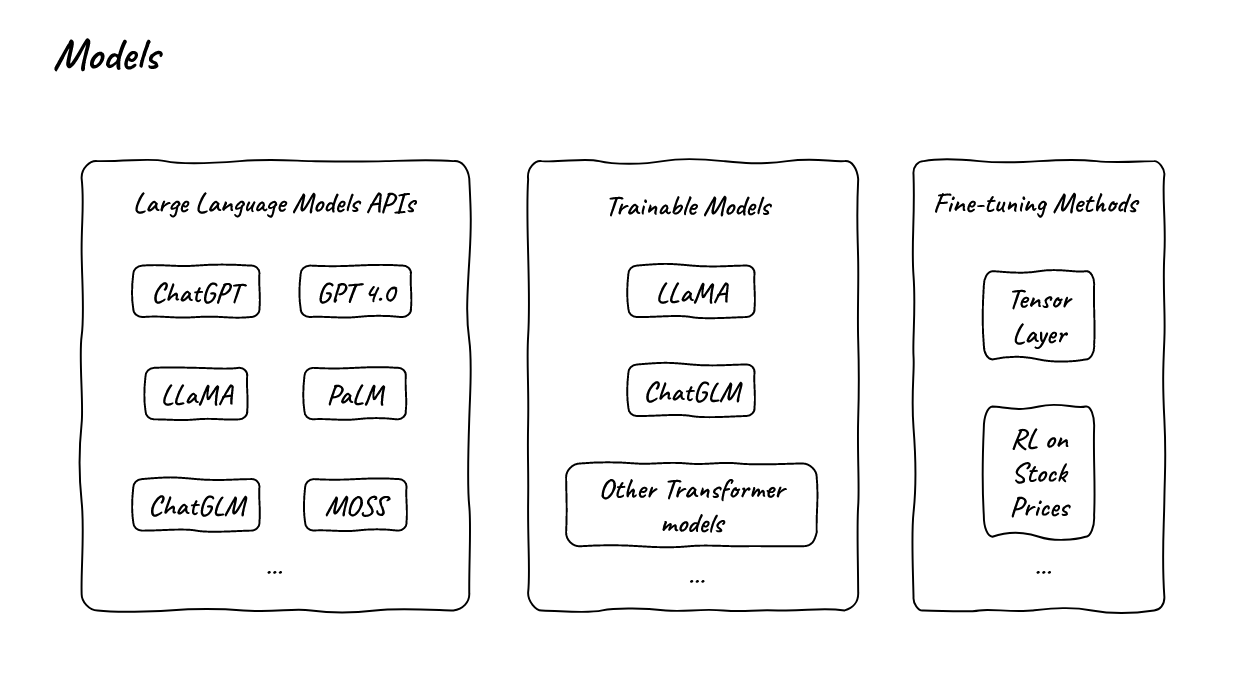
- In data-centric NLP, we don’t train the model from the beginning. We only call APIs and do light-weight fine-tunings.
- The left part is some LLM APIs that we may use and the middle part is the models that we may use to perform fine-tunings and the right part is some of the Fine-tuning methods
1. Fine-tuning: Tensor Layers (LoRA)
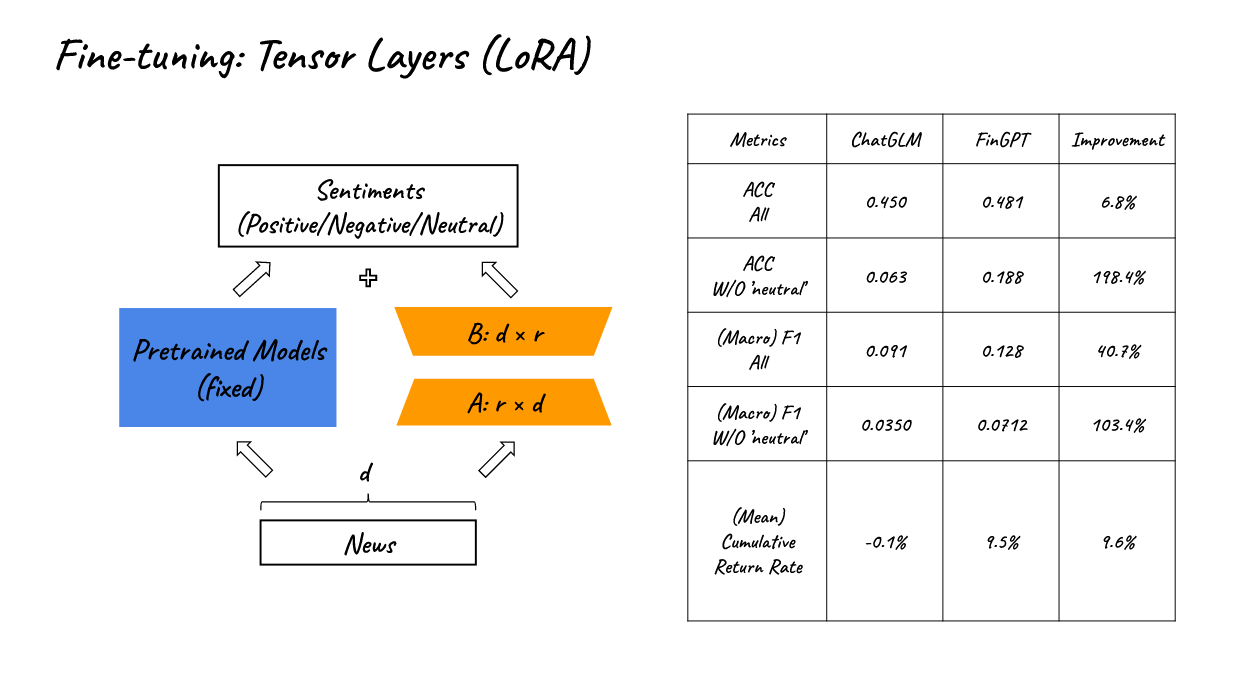
- In FinGPT, we fine-tune a pre-trained LLM using a new financial dataset.High-quality labeled data is one of the most important key to many successful LLMs including ChatGPT
- However, those high-quality labeled data are often very expensive and time-consuming and we may need help from professional finance experts.
- If our goal is to use LLMs to analyze financial-related text data and help with quantitative trading, why not let the market do the labeling for us?
- So here, we use the related stock price change percent of each news as the output label, we use the threshold to split the label into three groups positive, negative, and neutral, and use them and the label of the news sentiment.
- In correspondence, we also ask the model to select one of positive, negative, and neutral as the output in the prompt engineer part so we the make the best use of the pre-trained information
- By using LoRA we may reduced the trainable parameters from 6.17B to 3.67M
- As the table presents, compared with chatGLM, FinGPT can achieve large improvement on multiple metrics. it may be inappropriate to use our model to quantitative trading directly. Since most news titles are neutral, most of the original outputs of the LLMs are Neutral, so LLM perform poorly in positive and negative labels and those labels are what might be useful in quantitative trading.
- However, after fine-tuning, we have witness huge improvements in the prediction of positive and negative labels.
- That’s also why the model can achieve positive trading results.
2. Fine-tuning: Reinforcement Learning on Stock Prices (RLSP)
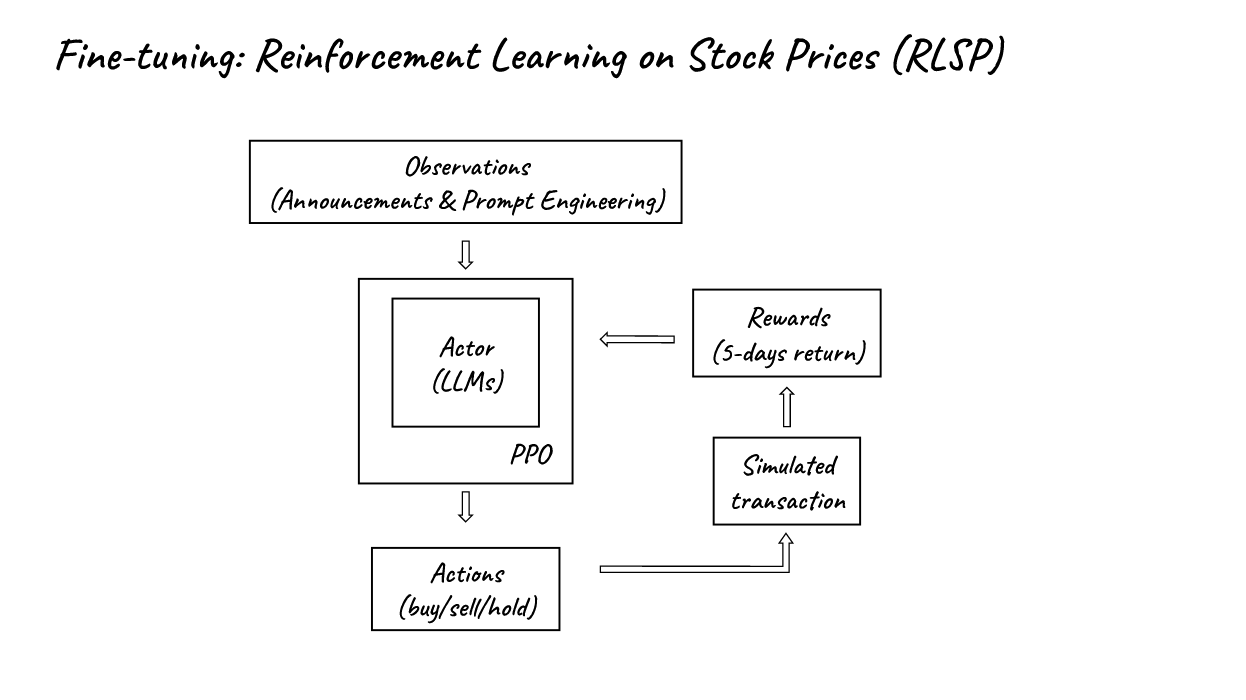
- In the same way, we may use RL on Stock Prices (RLSP) to replace RL on Human feedback used by ChatGPT.
Ⅳ. Applications
1. Robo Advisor
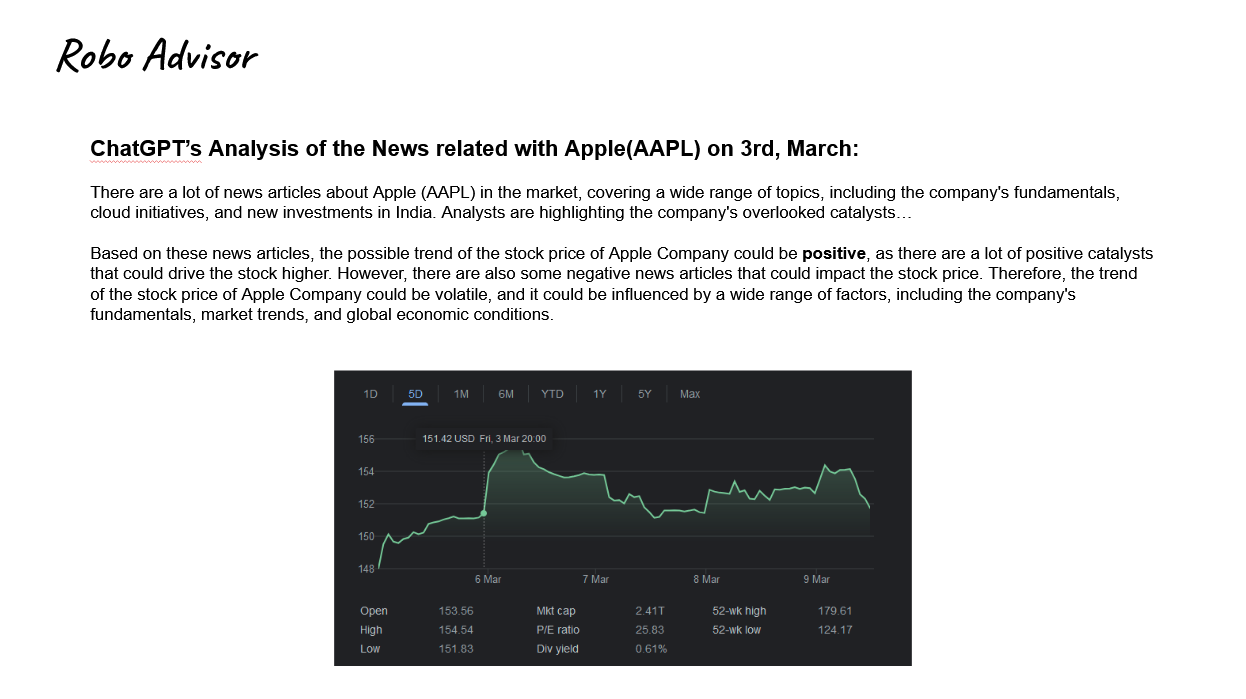
- ChatGPT can make the investment advises just like a pro.
- In this example the raising stock price of the Apple is in accordance with ChatGPT’s prediction made by the analysis of news
2. Quantitative Trading
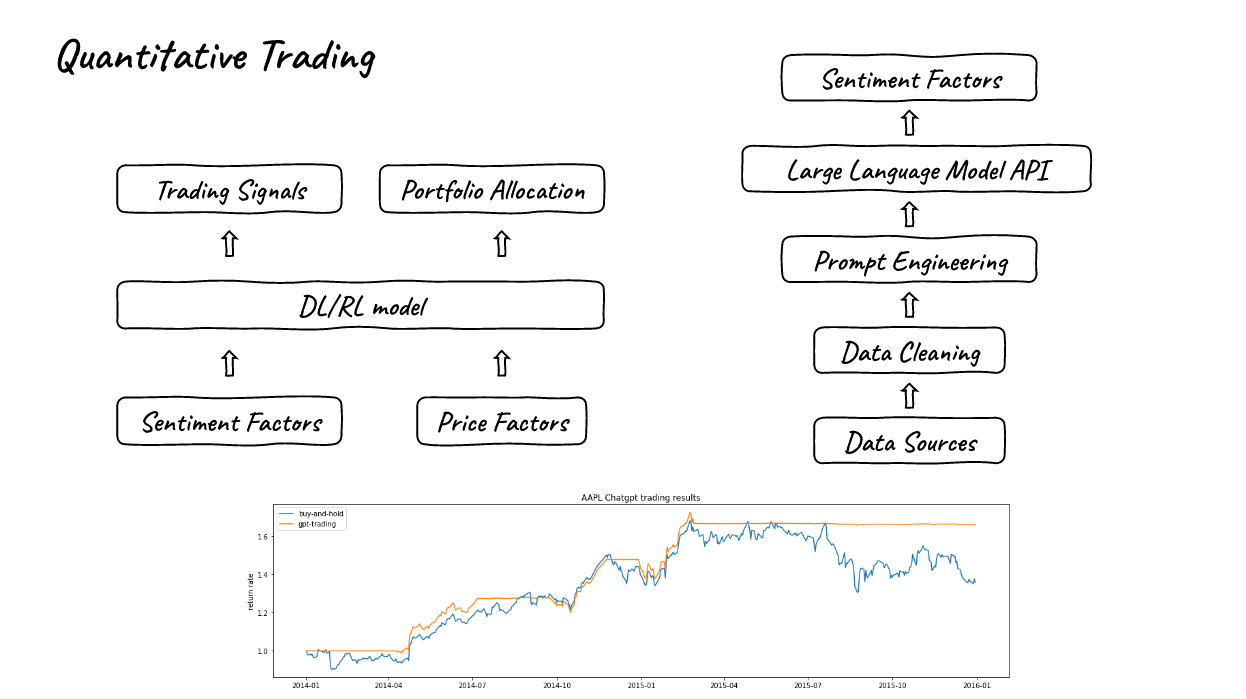
- We may also use News, Social media tweet or filing to build sentiment factors, the right part is the trading results just by the signal of the twitter tweets and ChatGPT, the data is from a data set called stocknet-dataset.
- As you may see from the picture, the trading signals generated by ChatGPT are so good that we may even achieve good results just by trading according to twitter sentiment factors.
- So we may even achieve better results by combining price factors.
3. Low-code development
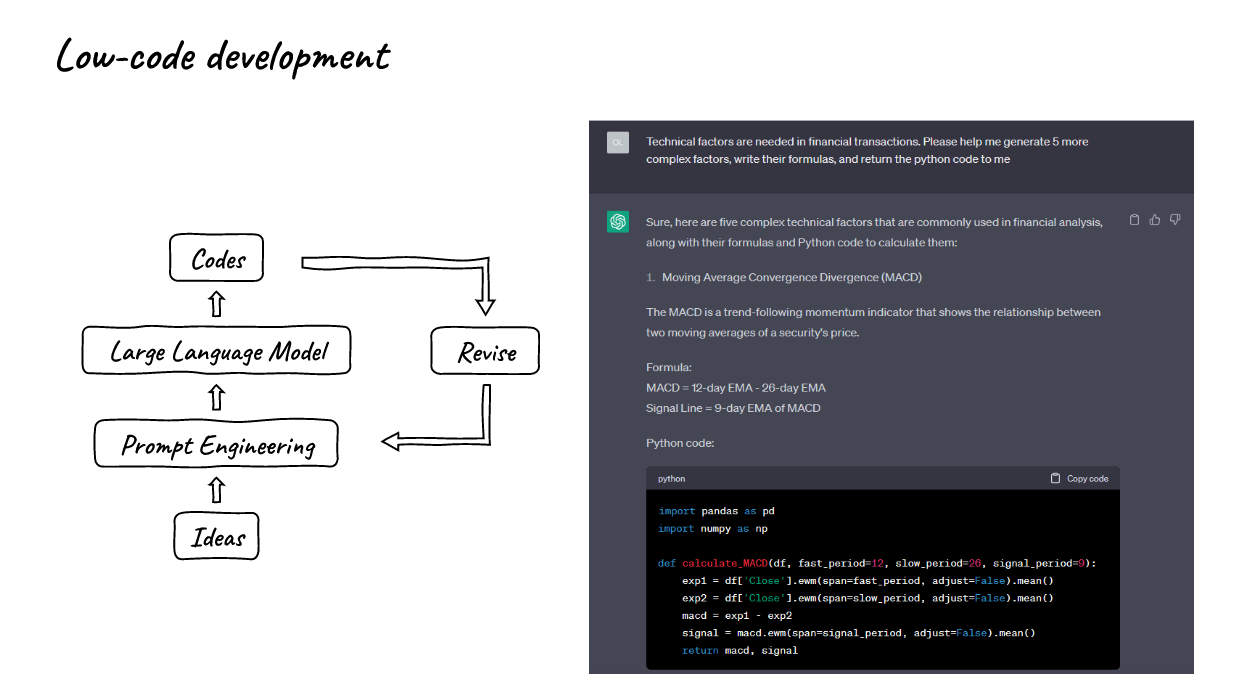
- We can use the help of LLMs to write codes.
- The right part shows how we can develop our factors and other codes quickly and efficiently.