互联网金融数据
演示内容请参见FinGPT
免责声明:我们根据MIT教育许可证的规定共享代码以供学术研究之用。此处不构成任何金融建议,亦非交易真实资金的推荐。在交易或投资之前请使用常识并首先咨询专业人士。
Ⅰ. 架构
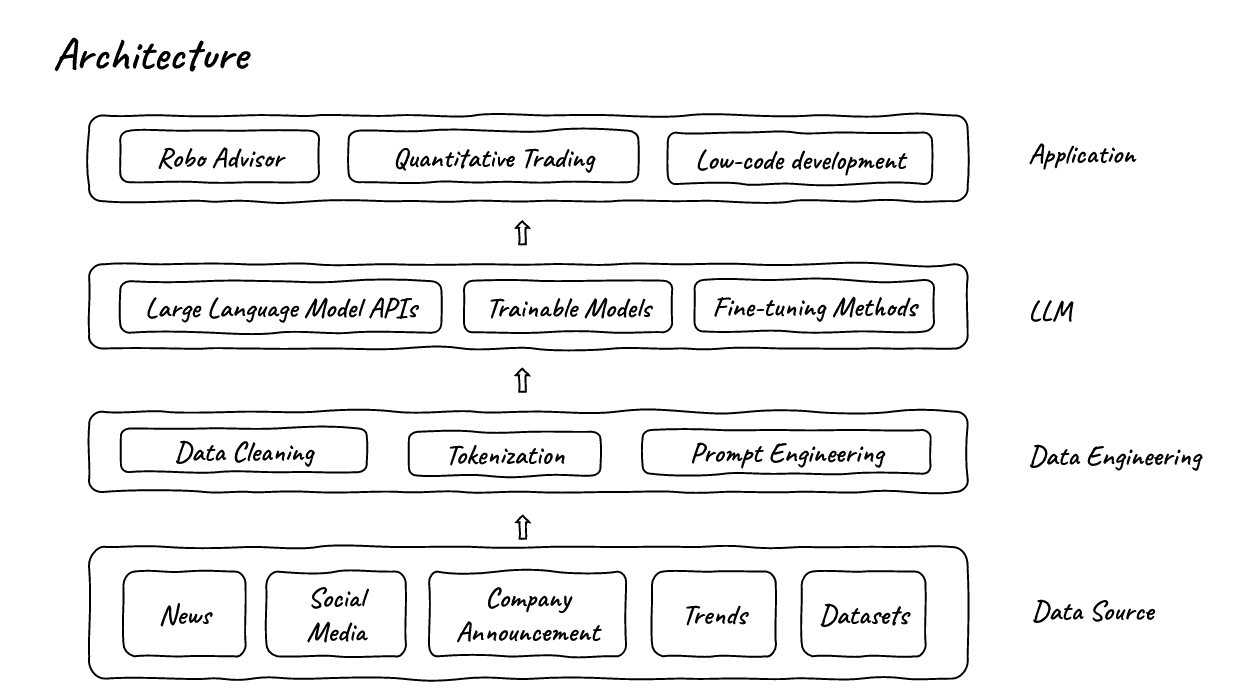
-
整个项目由4个部分组成:
-
第一部分是数据源,在这里,我们从互联网上收集历史和流媒体数据。
-
接下来,我们将数据推送到数据工程部分,在这里我们会对数据进行清洗,标记化处理和提示工程。
-
然后,数据被推送到大语言模型(LLMs)。在这里,我们可以以不同的方式使用LLMs。我们不仅可以使用收集到的数据来训练我们自己的轻量级微调模型,还可以使用这些数据和训练好的模型或LLM API来支持我们的应用程序。
-
最后一部分将是应用程序部分,我们可以使用数据和LLMs来制作许多有趣的应用程序。
Ⅱ. 数据源
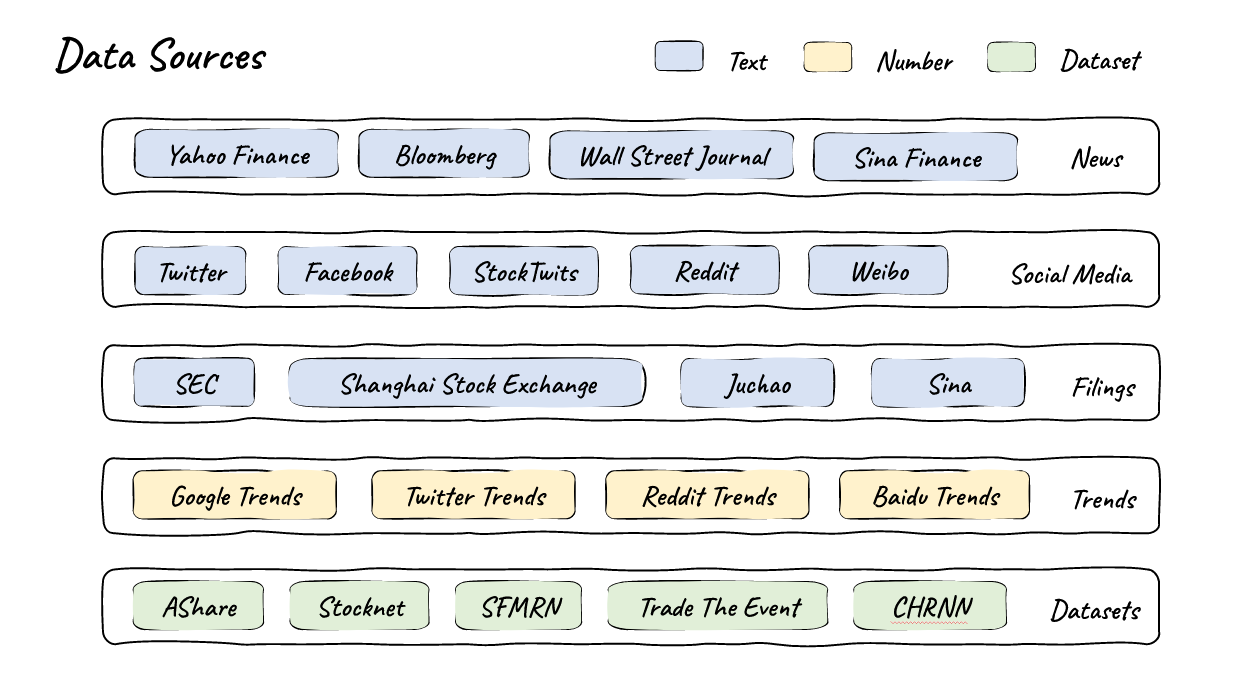
- 由于空间限制,我们只展示了其中一部分。
1. 新闻
| 平台 | 数据类型 | 相关市场 | 指定公司 | 时间范围 | 数据源类型 | 限制条件 | 文档数量(万) | 支持情况 |
|---|---|---|---|---|---|---|---|---|
| 雅虎 | 金融新闻 | 美国股票 | √ | 时间范围 | 官方 | N/A | 1,500+ | √ |
| 路透社 | 金融新闻 | 美国股票 | × | 时间范围 | 官方 | N/A | 1,500+ | √ |
| 新浪 | 金融新闻 | 中国股票 | × | 时间范围 | 官方 | N/A | 2,000+ | √ |
| 东方财富 | 金融新闻 | 中国股票 | √ | 时间范围 | 官方 | N/A | 1,000+ | √ |
| 第一财经 | 金融新闻 | 中国股票 | √ | 时间范围 | 官方 | N/A | 500+ | 即将 |
| 央视 | 政府新闻 | 中国股票 | × | 时间范围 | 第三方 | N/A | 4 | √ |
| 美国主流媒体 | 金融新闻 | 美国股票 | √ | 时间范围 | 第三方 | 账户 (免费) | 3,200+ | √ |
| 中国主流媒体 | 金融新闻 | 中国股票 | × | 时间范围 | 第三方 | ¥500/年 | 3000+ | √ |
- FinGPT可能比Bloomberg的文档数目更少,但我们在同一个数量级上。
2. 社交媒体
| 平台 | 数据类型 | 相关市场 | 指定公司 | 范围类型 | 来源类型 | 限制 | 文档 (1e4) | 支持 |
|---|---|---|---|---|---|---|---|---|
| 推文 | 美国股票 | √ | 时间范围 | 官方 | N/A | 18,000+ | √ | |
| StockTwits | 推文 | 美国股票 | √ | 最新 | 官方 | N/A | 160,000+ | √ |
| Reddit (wallstreetbets) | 帖子 | 美国股票 | × | 最新 | 官方 | N/A | 9+ | √ |
| 微博 | 推文 | 中国股票 | √ | 时间范围 | 官方 | Cookies | 1,400,000+ | √ |
| 微博 | 推文 | 中国股票 | √ | 最新 | 官方 | N/A | 1,400,000+ | √ |
- 在 BloomberGPT 中,他们不收集社交媒体数据,但我们认为公众舆论是干扰股票市场的最重要因素之一。
3. 公司公告
| 平台 | 数据类型 | 相关市场 | 指定公司 | 范围类型 | 数据来源 | 限制 | 文档数 (1e4) | 支持情况 |
|---|---|---|---|---|---|---|---|---|
| 巨潮网 (官方) | 文本 | 中国股票 | √ | 时间范围 | 官方 | N/A | 2,790+ | √ |
| 美国证监会 (官方) | 文本 | 美国股票 | √ | 时间范围 | 官方 | N/A | 1,440+ | √ |
- 由于我们从不同的股票市场收集数据,因此我们比Bloomberg GPT有更多的申报文档。
4. 趋势
| 平台 | 数据类型 | 相关市场 | 数据源 | 指定公司 | 范围类型 | 源类型 | 限制 |
|---|---|---|---|---|---|---|---|
| 谷歌趋势 | 指数 | 美国股票 | Google Trends | √ | 日期范围 | 官方 | N/A |
| 百度指数 | 指数 | 中国股票 | 即将推出 | - | - | - | - |
5. 数据集
| 数据源 | 类型 | 股票 | 日期 | 可用性 |
|---|---|---|---|---|
| AShare | 新闻 | 3680 | 2018-07-01 到 2021-11-30 | √ |
| stocknet-dataset | 推文 | 87 | 2014-01-02 到 2015-12-30 | √ |
| CHRNN | 推文 | 38 | 2017-01-03 到 2017-12-28 | √ |
Ⅲ. 模型
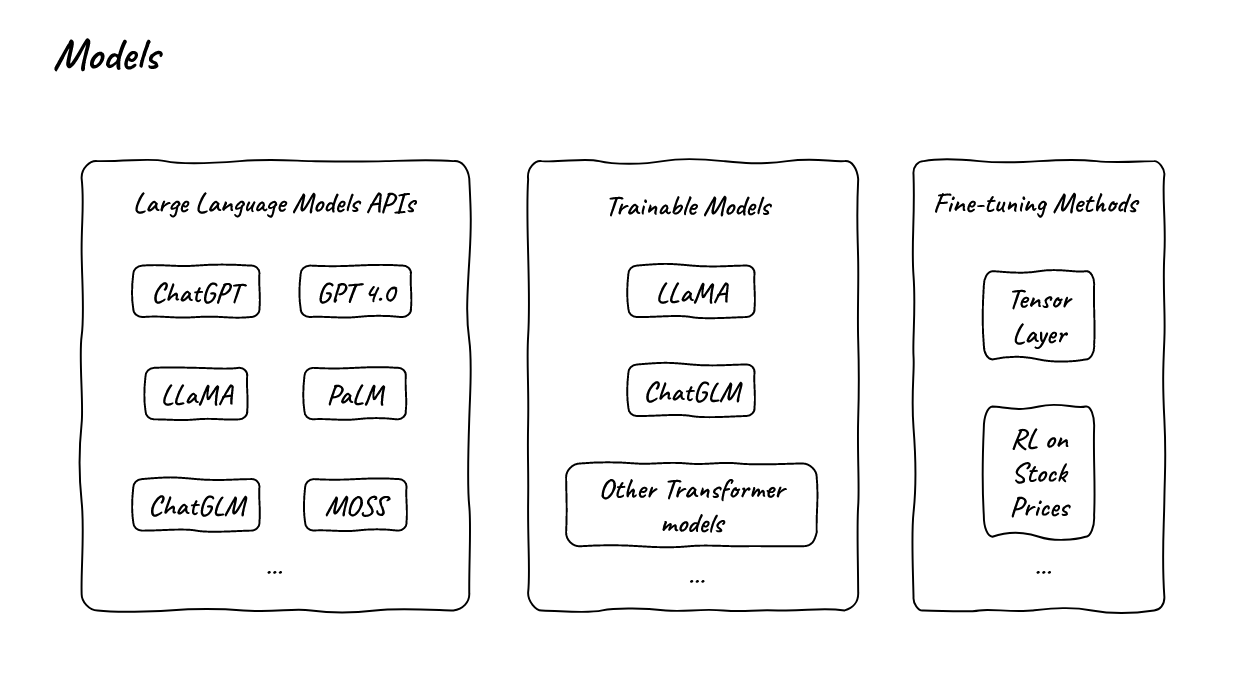
- 在数据中心的自然语言处理领域,我们不需要从头开始训练模型。我们只需要调用API和进行轻量级的微调。
- 左边是一些可能会用到的LLM APIs,中间是我们可能用来进行微调的模型,右边是一些微调方法。
1. 微调:Tensor Layers (LoRA)
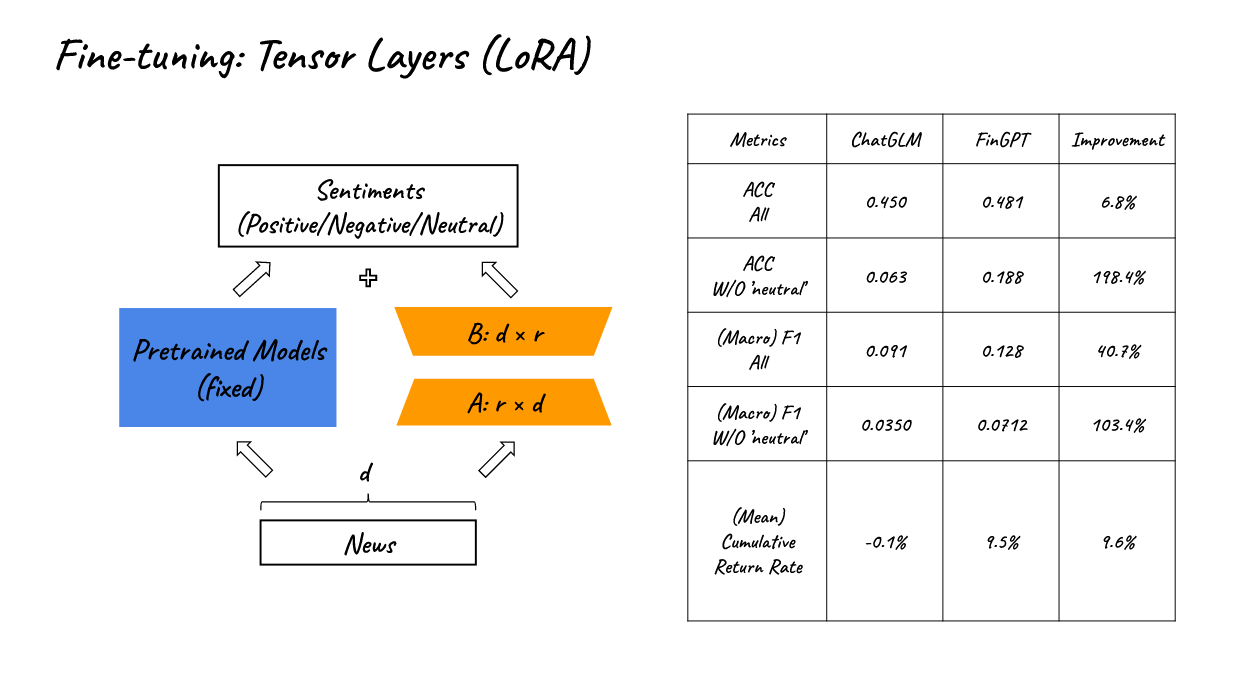
- 在FinGPT中,我们使用新的金融数据集对预训练的LLM进行微调。高质量的标记数据是许多成功的LLM(包括ChatGPT)的最重要的关键之一。
- 然而,这些高质量的标记数据通常非常昂贵和耗时,并且我们可能需要金融专家的帮助。
- 如果我们的目标是使用LLM分析与金融相关的文本数据并帮助量化交易,为什么不让市场为我们做标记呢?
- 因此,在这里,我们使用每个新闻相关的股票价格变化百分比作为输出标签,我们使用阈值将标签分成三组(积极的,消极的和中立的),并使用它们和新闻情感的标签。
- 相应地,在提示工程师部分,我们还要求模型选择其中一个正面的,负面的和中性的作为输出,以便我们充分利用预训练信息。
- 通过使用LoRA,我们可以将可训练参数减少从6.17B到3.67M。
- 如表格所示,与chatGLM相比,FinGPT可以在多个指标上实现大幅改善。然而,直接将我们的模型用于量化交易可能是不合适的。由于大多数新闻标题都是中性的,LLMs的大多数原始输出都是中性的,因此LLMs在积极和消极的标签上表现不佳,而这些标签可能对于量化交易是有用的。
- 然而,在微调之后,我们已经见证了在预测积极和消极标签方面的巨大改进。
- 这也是为什么该模型可以实现积极的交易结果的原因。
2. 微调:强化学习在股价上的应用 (RLSP)
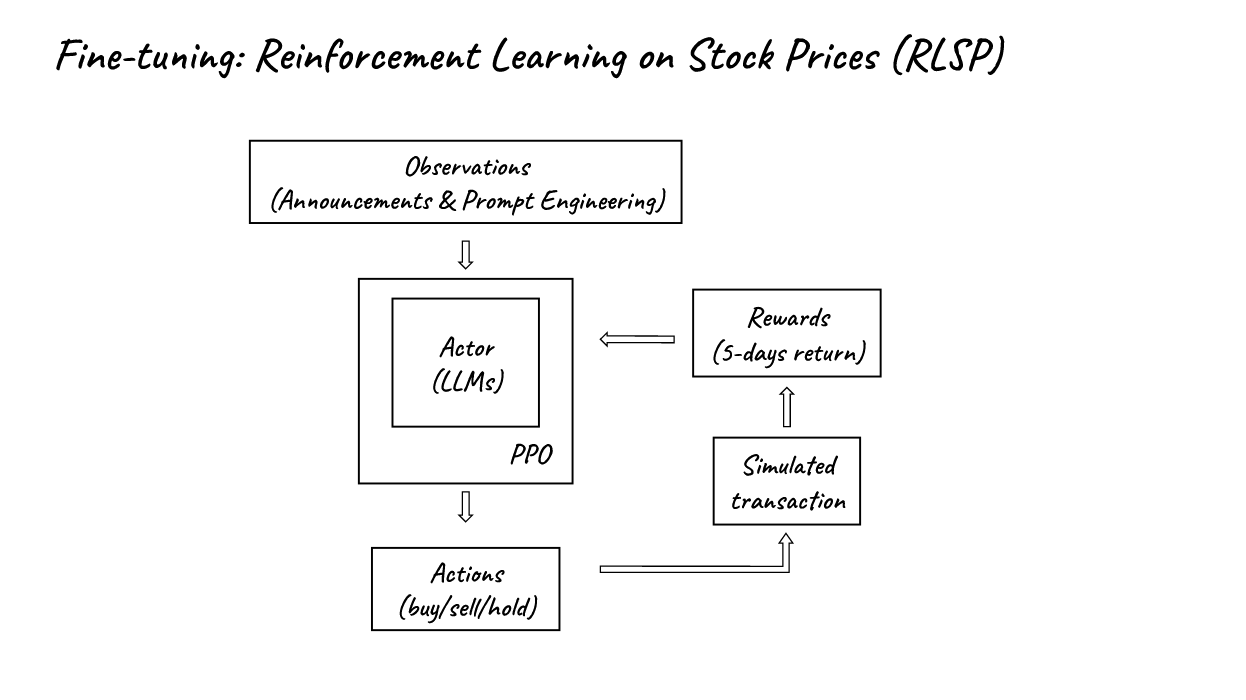
- 同样地,我们可以使用股价上的强化学习(RLSP)来替换ChatGPT中使用的人类反馈上的强化学习。
Ⅳ. 应用
1. 智能投顾
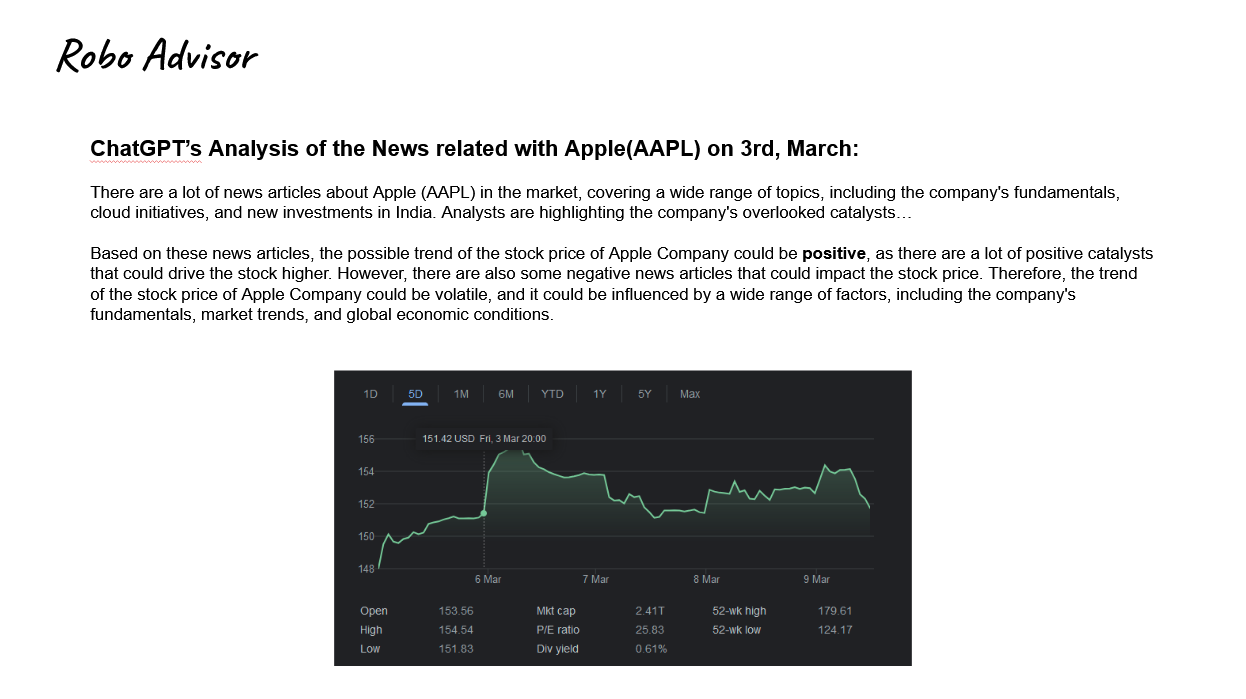
- ChatGPT可以像专业人士一样进行投资建议。
- 在这个例子中,苹果的股价上涨与ChatGPT分析新闻的预测相符。
2. 量化交易
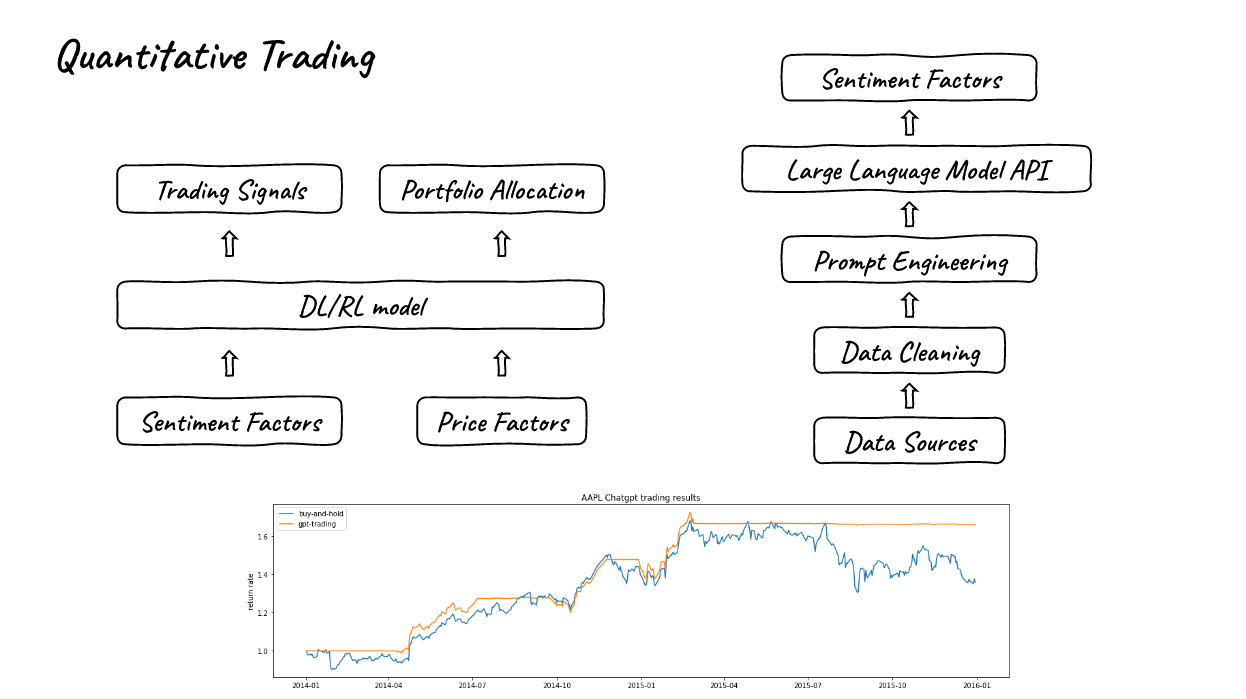
- 我们还可以使用新闻、社交媒体推文或者公司公告来构建情感因子,右侧的部分是由Twitter推文和ChatGPT信号产生的交易结果,数据来自于一个称为stocknet-dataset的数据集。
- 正如您从图片中所看到的,由ChatGPT生成的交易信号非常出色,我们甚至可以仅通过根据Twitter情感因子交易而获得良好的结果。
- 因此,我们可以通过结合价格因素来获得更好的结果。
3. 低代码开发
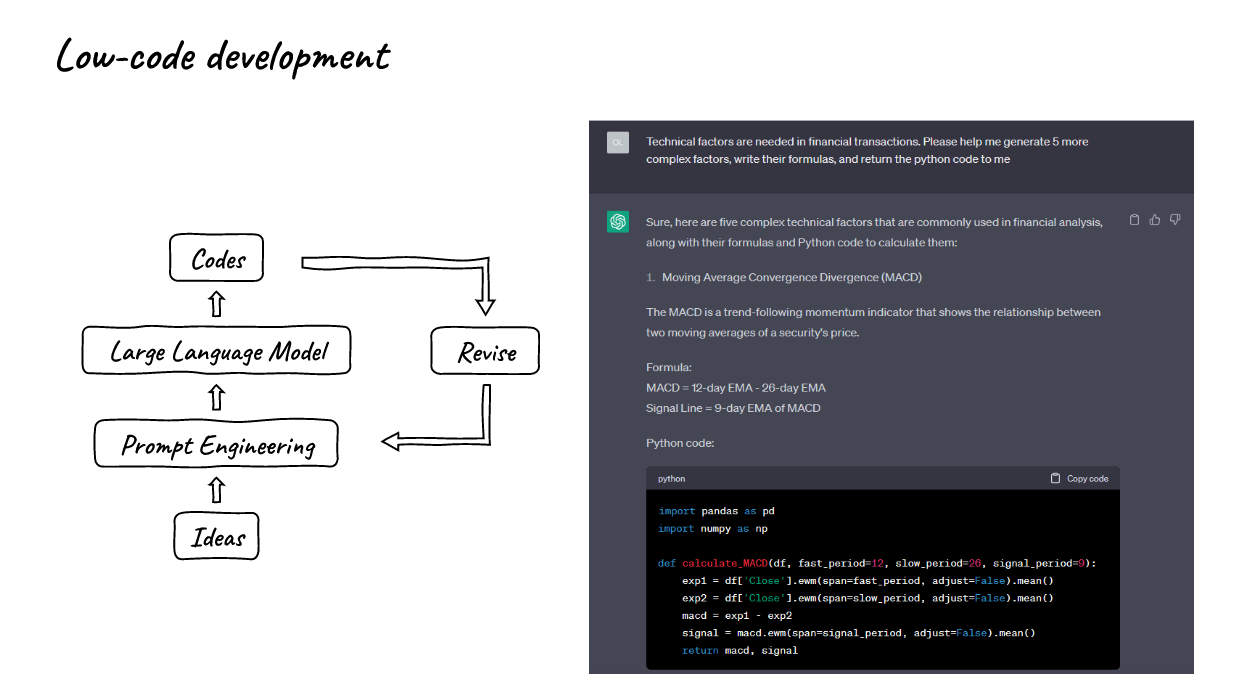
- 我们可以使用LLMs的帮助来编写代码。
- 右侧显示了我们如何快速高效地开发我们的因子和其他代码。